ML Model Serving at Scale
At Ultimate, in addition to LLMs and other embedding models, our customers operate one or more bots. We train and serve custom ML models for each bot utilizing our proprietary model training and serving/inferencing systems. Apart from ML models, we need to maintain various pre/post-processing components including bot-specific regexes. As one could imagine, serving thousands of ML models along with their custom pre/post-processing components via web services is a challenging task regarding efficiency and scalability.
There are several strategies for hosting/serving ML models (equivalent to bots in the Ultimate setting). Each strategy offers its unique advantages and disadvantages in terms of scalability and efficiency. In this article, I will succinctly explain different techniques, and present our approach designed to mitigate the limitations of other methods.
Approach 1: Distinct Web Service Deployments for Each Bot
The most straightforward approach for serving ML models is deploying a unique web service for each, in which an ML model and its associated pre/post-processing components are housed separately. This strategy works well for isolation purposes when only a few bots are involved. However, for thousands of bots/models, it becomes impractical due to:
- The ML libraries used for operating ML models require a significant amount of memory for their internal objects. As such, each ML model service deployment will have additional, unnecessary memory consumption due to ML and server libraries as follows:
- Approximately 350 MB of memory is needed to instantiate Tensorflow (v2.16.1).
- Roughly 120 MB of memory is necessary to instantiate PyTorch (v1.21.2).
- Any changes on the inference system (new features, bug fixes, etc.) would need to be replicated across numerous service deployments. This creates considerable overhead with regards to maintenance, monitoring, and deployment.
- Service updates (deployments/rollbacks) must be reflected across all services concurrently.
- A complicated and fragile setup is required for observability and monitoring.
- In addition to technical limitations, emerging business requirements may further compound service management overheads. When a new customer joins or an existing one leaves, new service deployments would need to be launched or existing ones decommissioned respectively. This adds to the complexity of managing the infrastructure.
Approach 2: Singular Web Service Deployment for All Bots
As we can see, the first method requires specific improvements, particularly in efficiency and maintenance. So, what if we loaded all bots (their ML models and pre/post-processing components) within the context of a single service deployment with replicas? This could undoubtedly enhance efficiency as we wouldn’t need to instantiate ML and service libraries multiple times, thus eliminating the hassle of dealing with rolling update procedures for thousands of separate services simultaneously. But is this an all-round solution? Unfortunately this is not a good solution either, as this approach introduces bigger challenges:
- Depending on the total number of Bots, the initialization time of inference containers could be excessively long.
- Memory usage of a single inference process might be massive as it needs to maintain numerous ML models and other custom components within the same processes.
- Any issue in the custom data pre/post-processing routines of a Bot could potentially harm the performance of all other bots, as they all share the same environment.
- Most importantly, this approach allows for only vertical scalability, and the memory usage of inference processes will be limited by the capacity of the underlying VM. Therefore, the advantages of horizontal scalability cannot be leveraged.
Although this strategy seems to resolve the issue of maintenance overhead and enhances efficiency, it introduces serious problems related to scalability.
Our Approach: Bot Sharding
Previous techniques, while having certain merits, also come with distinct challenges. To address these issues, we at Ultimate have embraced a hybrid approach, appropriately named Bot Sharding. This approach carries the benefits of both prior techniques. As the name indicates, with Bot Sharding, we distribute similar bots’ models across different inference service deployment pools and execute them solely within their respective pool. This method offers numerous advantages:
- As we can regulate the number of bots in each inference service deployment pool, we can adjust our services efficiently in accordance with underlying hardware limits (memory, CPU, etc.) and maintain control over service initialization times.
- Since we don’t need to load all bots into a singular service scope, we’re able to reap the benefits of horizontal scalability by simply introducing a new inference service deployment pool.
- Courtesy of diversified service deployments, we can set distinct constraints and thresholds for the inference pipeline of real-time and non-real time bots. This also allows us to independently scale each pool.
- As we initialize required ML libraries for each inference pool rather than for each Bot, we can utilize memory more efficiently.
- It considerably reduces the maintenance overhead (compared to Approach 1) as we are now managing a smaller number of service deployments. This allows us to allocate resources and time more effectively.
- Lastly, this approach provides enhanced isolation in terms of potential performance degradation due to unrelated bots. This aspect significantly enhances the overall performance and stability of each individual bot (w.r.t approach-2), leading to a smoother and more reliable service.
So, how do we achieve this?
Simply distributing bots to different inference deployments, which we refer to as ‘pools’, is not entirely adequate due to the varying requirements of our bots, such as real-time and non-real-time needs. Consequently, we have implemented another logical layer above the ‘pools’ concept known as ‘pool group’. Specifically, we maintain two pool groups: real-time pools and non-realtime pools. Each of these consists of multiple inference service deployment sets, as depicted below.
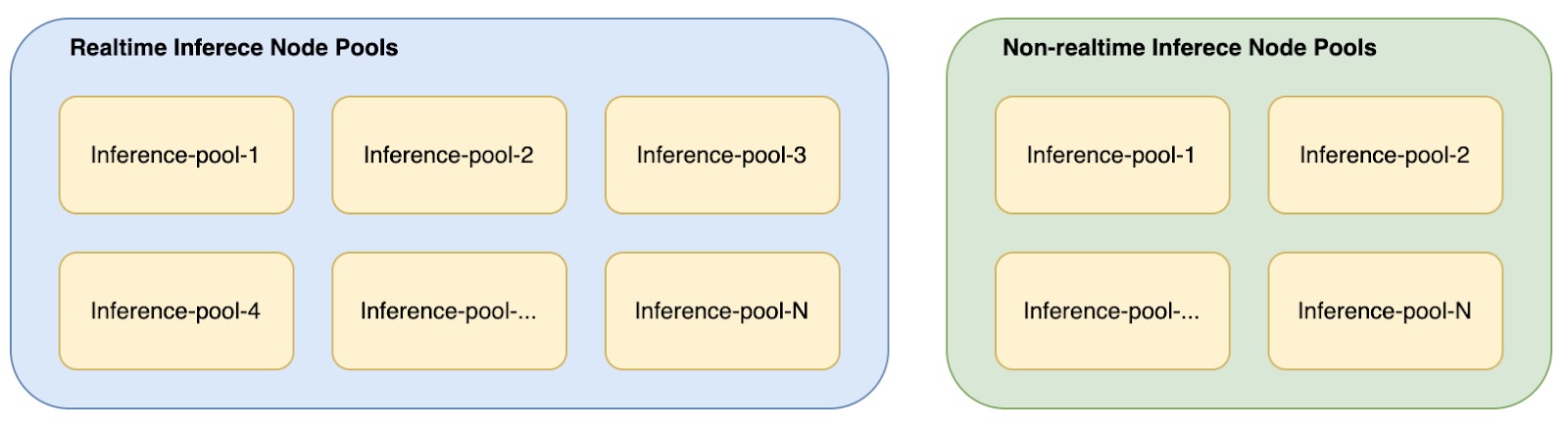
For bot assignment to inference pools, we employ an approach akin to Locality Sensitive Hashing. Essentially, our hash function uses the bot’s ID, real-time response requirements, and other properties as inputs, and generates a hash value which corresponds to the name of the relevant inference pool.
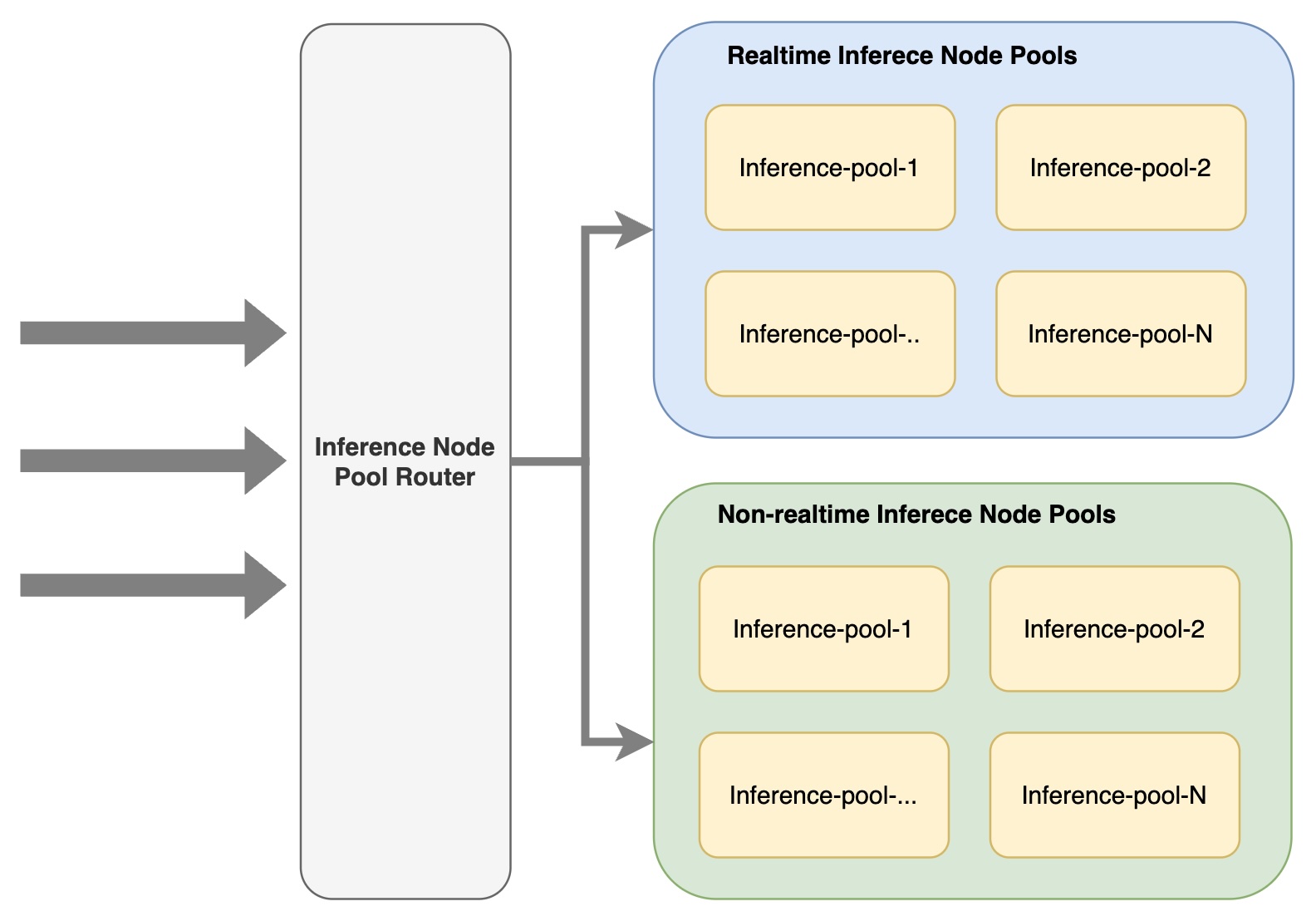
Different inference pools have unique hash suffixes and utilize the same hash function to load only the relevant bots during their initialization and throughout their lifecycle. To redirect incoming inference requests to the appropriate pools, we have another component, the inference router. Similar to other components, based on various bot properties, it generates a hash value and redirects requests to the pertinent inference pool.
Conclusion
Utilizing a hybrid approach for hosting bots (models) has enabled us to benefit from horizontal scalability and efficient memory utilization. Additionally, it allows us to mitigate and isolate the effect of malfunctioning components, thereby enhancing the performance and reliability of our system.