What Is Language Detection?
Language Detection is the task of automatically detecting the language(s) present in a document based on the content of the document. Computational approaches to this problem view it as a special case of text categorization, solved with various statistical methods.
Language Detection is not the hardest task in NLP as language can be detected correctly over 99% of the time for well-written long texts. However, Language Detection in chat can be quite difficult. One of the most important problems is the short text, which contains only one or a few words.
Having good results on short text is crucial, since the most common situation in a conversational chat bot is short interactions between the bot and the user. Multilingual text, where the user mixes more than one language when chatting with the bot, is challenging for Language Detection as well. Additionally, distinguishing between closely related languages such as Spanish and Catalan, or Serbian and Croatian can be a challenge.
What do we need in a language detection model?
For selecting the best Language Detection method for us we have to take into account the following requirements:
- The language model should cover all the languages that our product can handle (109 languages).
- The model should be very accurate even if the message contains only one or two words.
- The model should have a small size to reduce its cost as much as possible.
- The model should be real-time. This is very important to avoid having a bottleneck in the chat flow.
Reviewing existing tools
Language Detection has been extensively studied in the literature. In the beginning, all of the research was done on long, well-written, clean sentences and paragraphs. Therefore, the results were rather impressive. During the past decades, the usage of text messages and social media platforms has exponentially increased.
NLP tasks on social media text are challenging because the text is very short, and contains a lot of different challenges such as slang, misspelled words, acronyms, etc. Of course, the Language Detection performance drastically drops on chat and social media platforms’ text.
There are several Language Detection tools available in the market. We collected them into a table and reviewed them from their applicability: accuracy, speed, number of supported languages, and environmental requirements.
| Tool name | Cost | Hosting | Languages | General Accuracy | Accuracy on short text | Speed (10k text/s) |
|---|---|---|---|---|---|---|
| Lingua | Free | Local | 75 | High | High | Very slow |
| No language left behind (fastText model) | Free | Local | 200 | Medium | Medium | Very slow |
| Franc | Free | Local | 82, 187 or 403 | Medium | Recommended to be used only with long texts | Very slow |
| Google API | Not Free | API | 100+ | Very accurate | Very accurate | Fast |
| Langdetect | Free | Local | 49 | Low | Low | Very slow |
| Langid | Free | Local | 97 | Low | Low | Slow |
| pycld2 | Free | Local | 80 | Medium | Low | Very fast |
| gcld3 | Free | Local | 107 | Medium | Low | Slow |
| fastText - lid.176.bin | Free | Local | 176 | Good | Low | Fast |
| fastText - lid.176.ftz | Free | Local | 176 | Good | Low | Fast |
There are a lot of other Language Detection APIs that can be purchased and we aren’t listing them here, because their performance is unknown.
Based on the review, we concluded that there is no ready-to-use solution for us. None of them can work on short texts with high speed and good quality for multiple languages. Therefore we decided to build a Language Detection model in-house.
Why is Language Detection so Difficult in Chat?
Before designing the Language Detection Model, we identified the key challenges of general Language Detection tools and why their performance is so bad on chat messages.
The first and most trivial problem is that messages are very short - strings composed of a few characters are often present in more than one language, making reliable identification challenging:
api - This is an Indonesian word with meaning “fire”, but also an English abbreviation for “application programming interface”.
Often times chat users will type a message like a query instead writing complete sentences:
“Login issue” instead of “I can not login to my account.”
In addition, most of the short messages are greetings. Greeting causes a huge problem for Language Detection models, especially since a lot of users use English, Italian, or Spanish greetings even if they would like to chat in a different language for example in German:
Greetings like “Hi”, “Hello”, “Ciao”, “Hola”, “Bonjour” etc. are common in many languages.
The second major challenge is the domain mismatch. Most Language Detection tools were trained on Wikipedia (Wikipedia, Tatoeba, Wili-2018). Wikipedia is well-written with complete sentences and uses a very general vocabulary. It is easy to see, that the chat domain is the opposite of Wikipedia. The customer support domain uses a very specific vocabulary with special technical terms and varying word usage.
There aren’t too many examples from Wikipedia about “login problem“, “reset password“, “delivery issues“, etc.
In addition, chat messages contain noise such as typos, abbreviations, non-standard words, false starts, repetitions, missing punctuations, missing letter case information, pauses, filling words such as “um” and “uh”.
Noise leads to confusion in text messages and the Language Detection model.
Examples could include “knsultant”, “cumschimbparolainoptimal”, “want deliveri”, “cn i get ma ordr statos”, “hey wan raise ccredit llimit”
The third problem is that most Language Detection models have a huge bias toward English or other European languages. That means that models prefer English over other languages. The bias comes from the training data structure where the English examples are overrepresented. For example, the fastText model has an enormous bias toward English.
fasttext prediction on “9999999” is English with 0.357 confidence.
The fourth challenge we identified is that Language Detection models are not well-calibrated. The calibration tells us whether we should or shouldn’t trust our model prediction. All of the models produce some kind of confidence score during prediction, which shows how certain the model is about the predicted language. The problem comes when the model is always very confident about the prediction even if the prediction is a mistake. We should have a model that we can trust.
When a model is well-calibrated, the confidence score should equal the accuracy. For example, if your test set has 100 examples for which the model predicts 0.8, the accuracy over those 100 examples should be 80%. In other words, if 0.8 is a true probability, the model should get 20% of these examples wrong! For all the examples with a confidence score of 0.9, the accuracy should be 90%, and so on.
Our Journey: Design Tips and Tricks
1. Choosing a Classifier Model
When we started to design our Language Detection tool, we were certain that we would like to have a classification model that is fast, easy to train, and already proven to work well in detecting languages. Based on some previous benchmarking work from literature ( e.g Comparison of language identification models, Language Identification for very short texts: a review ) fastText seemed to be a great choice for the Language Detection task.
fastText is an open-source and simple classifier for text classification but also achieves competitive performance in various NLP tasks. The fast training and running speed is largely due to its simple architecture (see below).
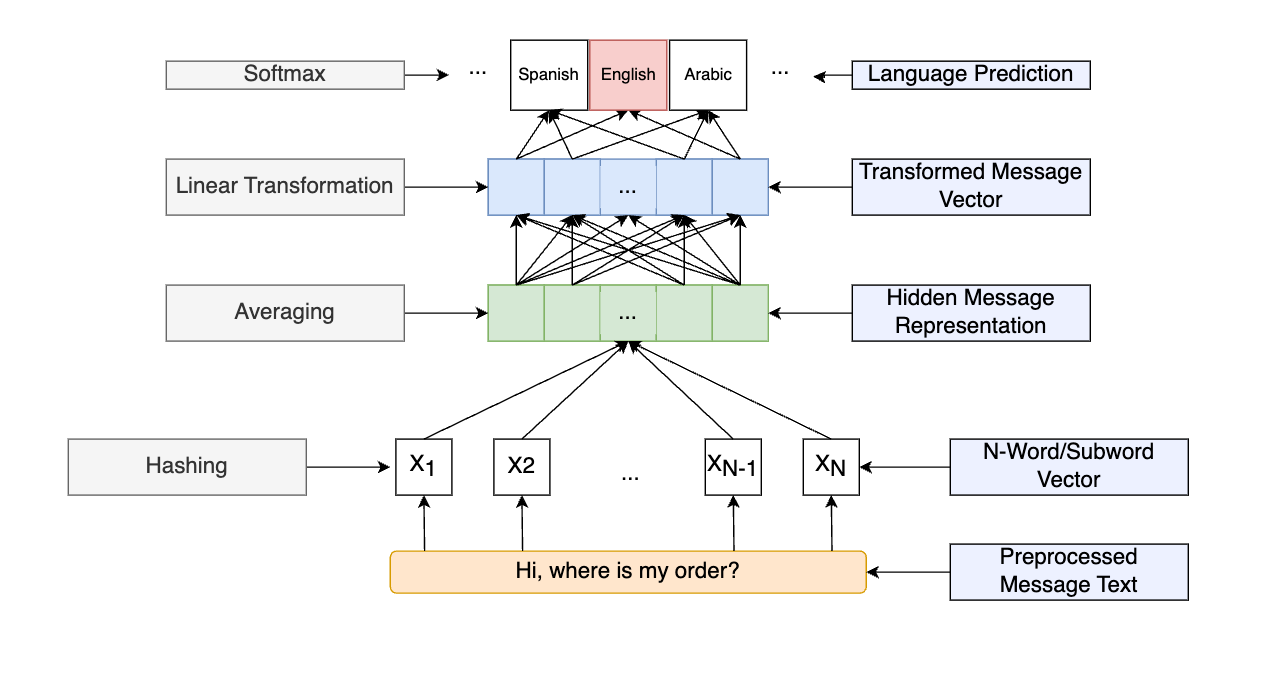
2. How should we feed text into the Classifier?
For us, one of the biggest questions was how we should feed text to the Base-model to get the best language representation: in other words how the text should be split into smaller chunks.
The first and most native solution would be to split the text into words. Using words as tokens is very problematic: you can only learn those words that are in your training vocabulary (out-of-vocabulary: words that are not in the training set
“I am” -> “I’m”
“cat” -> “cats“
Word representation is more difficult for morphologically rich languages such as Hungarian or Finnish:
auto: car
autoni: my car
autossa: in a car
autossani: in my car
autoissani: in my cars
Although you could address this by applying stemming or lemmatization to your input text to reduce the size of your vocabulary, due to the lack of multilingual lemmatizers which have a good performance for each language, that wouldn’t be a good solution. Further problems are compound words (e.g. der Kühl/Schrank) and abbreviations (e.g. API), and some languages can not be segmented by space such as Chinese, Japanese, and Korean.
Another option could be to split the text into characters. This would solve the large vocabulary problem, and we won’t produce unknown words during prediction (each word can be build up from characters). The main critique against character representation is the letters may be combined into chunks (such as n-grams) that do not exist or are not correct words. Another critique is that character representation takes more resources: for a 5-word long sentence, you may need to process 30 tokens instead of 5-word-based tokens. Additionally, some languages use almost the same character set, and on the character level, it would be very hard to distinguish them.
In summary, it would be great if we could offer an approach between word and character known as subword-level tokenization. The subword-level tokenizer deals with an infinite potential vocabulary via a finite list of known words. The main recognition is that words can be built from smaller words/units just like Lego and can be learned in an unsupervised way without any language knowledge:

It needs to remember a limited number of words and put them together to create the other words. So instead of using the usual text representation of Language Detection, we are using a subword-level tokenizer. Byte-Pair subword tokenizer (BPE) is one of the most popular subword-level tokenizers. Byte-Pair Token Learning begins with a vocabulary that is just a set of individual characters (tokens). It then runs over a training corpus k times and each time, it merges 2 tokens that occur the most frequently in the text. e.g. “e” and “r” are merged into a single token “er” when they occur together in the same order.
- Byte-Pair subword tokenizer tackles Out-of-vocabulary (OOV) effectively. It segments OOV as subwords and represents the word in terms of these subwords.
- The length of input and output sentences after BPE are shorter compared to character tokenization.
BPE brings the perfect balance between character- and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “Unknown: UNK” tokens. This especially applies to foreign languages like German where the presence of many compound words can make it hard to learn a rich vocabulary otherwise.
A fastText-based-model is not able to take into account token order in the text. Each token is handled separately in bag-of-words representation:
It is easy to get that this is an English sentence: “I like you“.
And now?: “iekl ou y“
In language detection the word order is important, we add an n-gram representation of the tokens to the base model. Let’s see how our feature generation works:
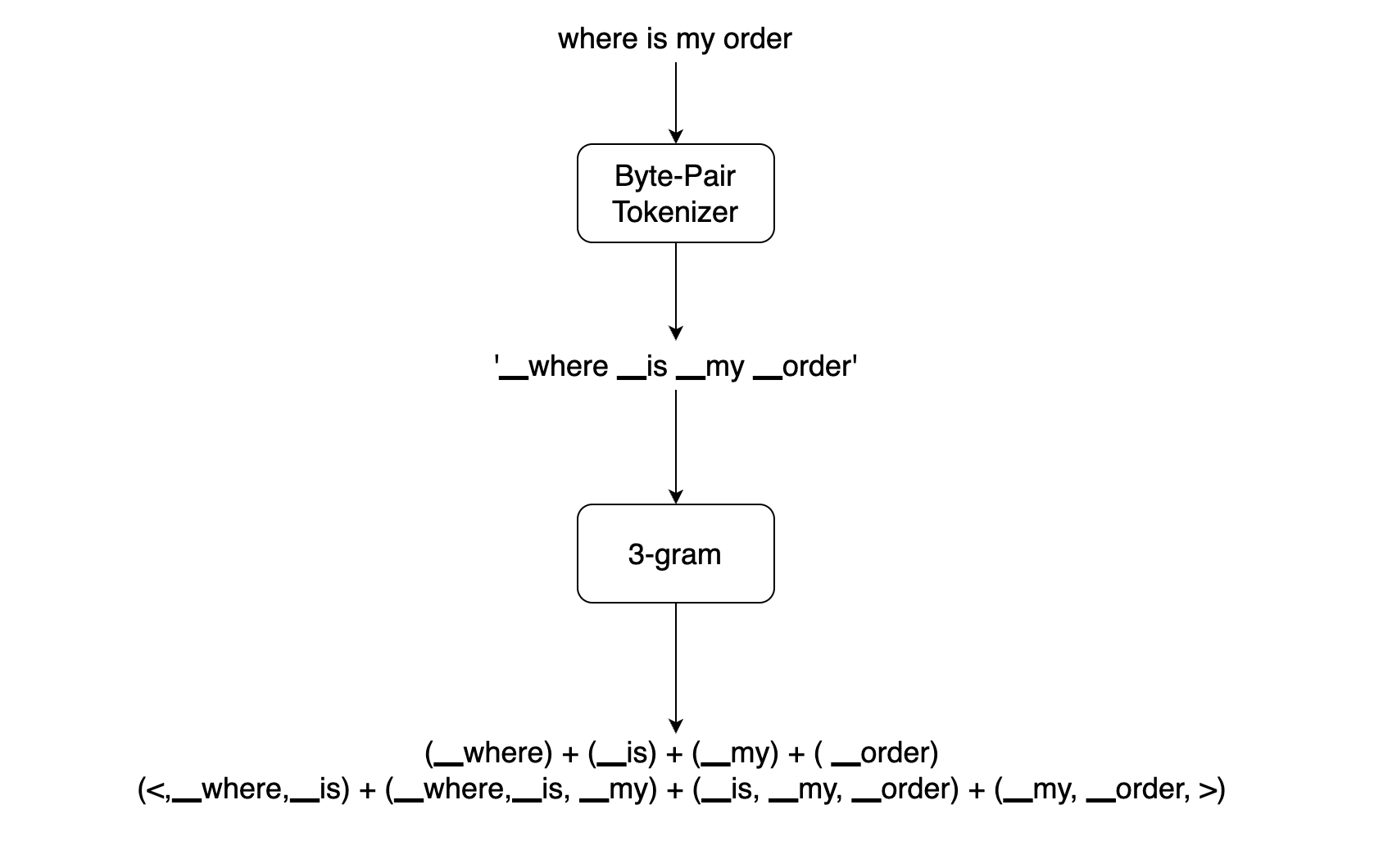
Since there can be a huge number of unique n-grams, we apply hashing to bound the memory requirements. Instead of learning an embedding for each unique n-gram, we learn total B embeddings where B denotes the bucket size (usually the bucket is around 2 million).
3. Dealing with Domain Mismatch and Biases
As we saw, the biggest problem of the Language Detection model is the domain mismatch which includes the short message problem as well. There is a bunch of work to solve domain mismatch in AI. The most successful solution is to create a proper training dataset that fits very well to the task domain. Of course, it is not always possible due to the lack of existing in-domain datasets. In our cases, we combined two datasets together. The main part of our training data is coming from the OpenSubtitles dataset. It contains movie and TV subtitles in multiple languages. The content is more like a natural conversation with short sentences and greetings. This dataset was a good starting point for having a source for training the Language Detection model. However, we had some kind of domain mismatch: just imagine how often people in the movie asked about login issues, reset passwords, or item delivery. To get closer or target domains, we added customer service data as well. Our dataset ended up containing around 145 million samples where the languages are balanced.
With a careful dataset design, we solved the following issues:
- The model performance was increased in general, especially on short messages.
- The domain mismatch between the model and the chat domain was decreased.
- Those languages that are not relevant to our business such as Latin and Esperanto were excluded.
- The massive bias on English which has in the off-the-shelf fastText pretrained model was removed.
4. Removing noise from text
As we see, noise is one of the most problematic issues for the Language Detection model, but the easiest problem that we can solve. We divided the noise problem into two parts.
The first part are the easy cases that can be solved by applying text filtering/cleaning processes such as removing new lines, tabs, URLs, digits, punctuations, and emojis.
The second part are the misspelled word cases. To increase the model’s resilience against noise we boosted our training set by applying the dropout function during tokenization. For one sample, we generate two tokenizations by using dropout:
“this is a sentence“ tokenized twice with dropout:
‘▁this ▁is ▁a ▁sentence’
‘▁this ▁is ▁a ▁sente n ce’
5. Dealing with Greetings
Greetings are still causing a lot of mistakes in Language Detection, even though we did a lot of work around in-domain training or text cleaning. Therefore, we built a specific greeting dictionary for all our needed languages (3500 greetings). In a dictionary, the keys are the greetings and the values are the possible languages ordered by their probability:
“ciao“: [“Italian“, “German“, etc.]
6. Can we trust our model?
The last but not the least problem is model calibration. The Language Model should be well-calibrated to be trustable during usage. We measured that the fastText model is usually overconfident. An overfitted algorithm leads to an overconfident model when the learner is more confident in its prediction than what the data depicts, in other words, overconfidence is a situation where the model will predict a wrong label with higher confidence. Therefore, we introduced two ideas to combat overconfidence.
The first one is to use some kind of dropout on highly frequent tokens during training, which helps the model combat overfitting. The other idea was to use dropout during the tokenized training dataset, as described previously.
With these two methods, our model became much more trustable: basically, our calibration error is around 1%.
Benchmarking Language Models
To compare all available Language Detection models to our model we evaluate them on two kinds of datasets. Since the goal is to have a good Language Detection model for the chat domain, the first dataset is an in-house dataset that has specific vocabulary from chats in English, Spanish, French, Finnish, and German (in a total of 2800 samples). Most of them are single words, word pairs, or very short sentences. The second dataset has a generic domain (standard vocabulary) called the Lingua test set: a standardized test set from the Lingua package that contains one-word, two-word, and short sentences for 75 languages.
With these two datasets, we can test how our models performance recognizing languages from domain-specific chats or from general texts.
Model and Tools for Benchmarking
To benchmark our Language Detection model we compare it to:
Language Detection models with a low number of languages supported were left out of this comparison. Lingua is noticeably slower than other language detectors, therefore we had to use Lingua withLowAccuracyMode feature that allows running Lingua faster (without this feature Lingua speed is enormously slow). For a fair comparison, we collected the Lingua large model accuracies from their reports for 45 languages.
To compare Language Detection models, we measured their accuracy and speed.
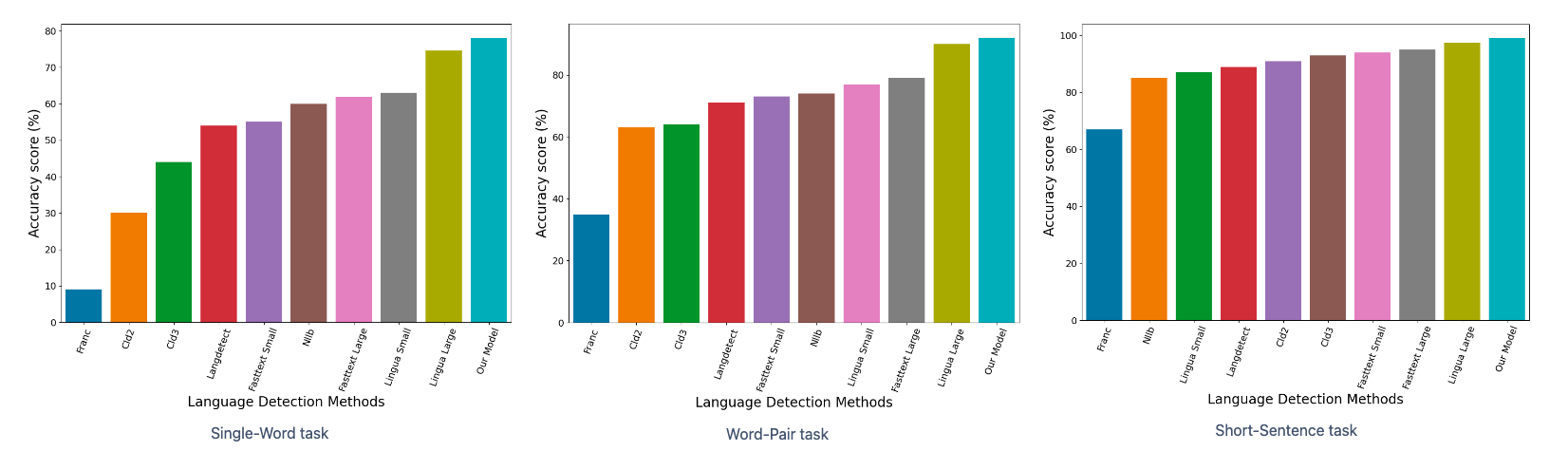
Benchmarking on our in-house dataset
The following figure shows that our Language Detection model has the best performance against the other models. We can say that we achieved our goal to have a very accurate Language Detection model in our domain.
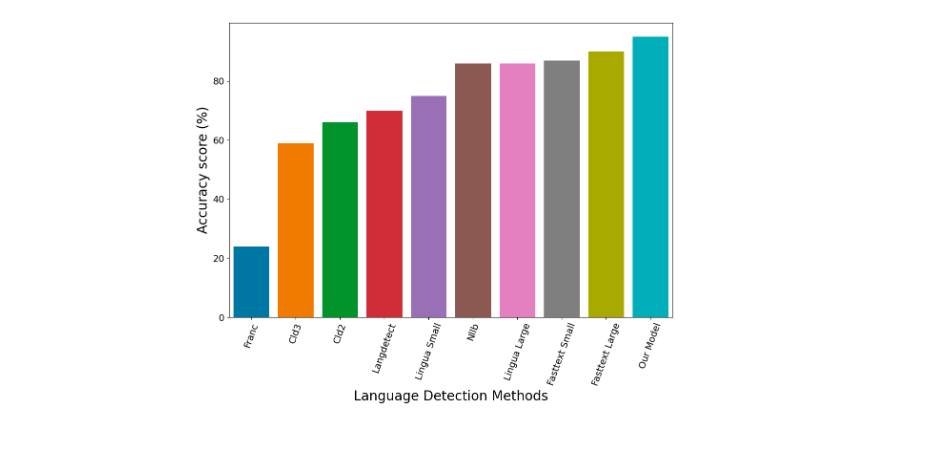
Benchmarking on the Lingua test set
As we can see in the following figure, our Language Detection model is the best regarding the accuracy, in other words, our model is the most accurate Language Detection model in the generic domain as well.
Comparing speed of models
In production, not only the model accuracy is important but the speed as well. The Language Detection component can not be a bottleneck of the chat flow it has to be very fast. From the comparison (see below) we can see that cld2 is the fastest model, then the fasttext-base models come. The worst are the langdetect, and lingua models regarding speed.
Our model can predict 28359 samples within 1 second.
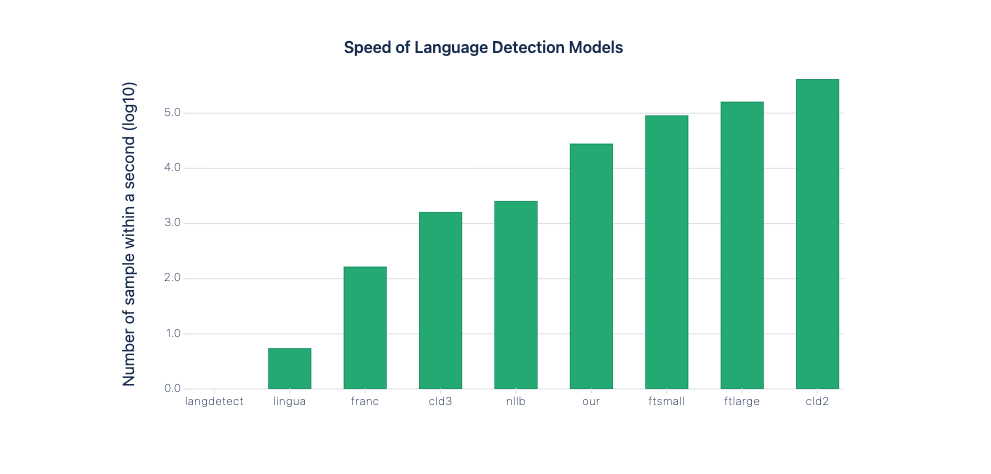
| Language Detection Models | Number of samples within a second | Number of samples within a second (in log10 scale) |
|---|---|---|
| langdetect | 0.42 | 0 |
| lingua | 5.52 | 0.741 |
| franc | 167 | 2.22 |
| cld3 | 1631 | 3.21 |
| nllb | 2612 | 3.41 |
| our model | 28359 | 4.45 |
| ftsmall | 92532 | 4.96 |
| ftlarge | 165477 | 5.21 |
| cld2 | 418809 | 5.62 |
Summary
We presented our journey and shared some tips and tricks on how we could improve the Language Detection model performance and on how to develop a model that is currently the most accurate, very fast state-of-the-art solution.
We demonstrated that with an old-school model like fastText, but with careful training data design, text processing, and some tricks we can achieve excellent results.
Through two benchmarking results, we showed that our model is not only the best in the chat-specific domain but in the generic domain as well.
In summary, our model is the most accurate Language Detection in all cases. With the new model, Language Detection is almost solved on long messages, on short messages it has the best performance in the field.
Of course, no Language Detection model can work 100% accurately, there will always be cases where the model becomes uncertain, and makes mistakes. In these cases, our chat platform helps and guides the user in finding the best way to connect to the chatbot and ensure the continuity of the conversation.